設計理念
為提升遊戲的互動性與挑戰性,我們設計了影像辨識系統, 玩家需於現實場景中拍攝圖片並上傳至遊戲,系統將自動辨識場景是否符合任務需求,推動劇情發展。
.png)
資料收集與預處理
資料蒐集自學校五大場景(如羅馬劇場、天地之間等),加入了不同時間(早、中、晚)及天氣條件,增強模型泛化能力。 圖片壓縮為 80x80 彩色圖像,訓練過程設置 50 個訓練週期,並保存最佳模型。
.png)
處理前和後的結果
.png)
.png)
模型訓練與成果
下圖為四種模型在訓練期間的 Loss 值變化比較:
.png)
下圖為四種模型在訓練期間的 accuracy 值變化比較:
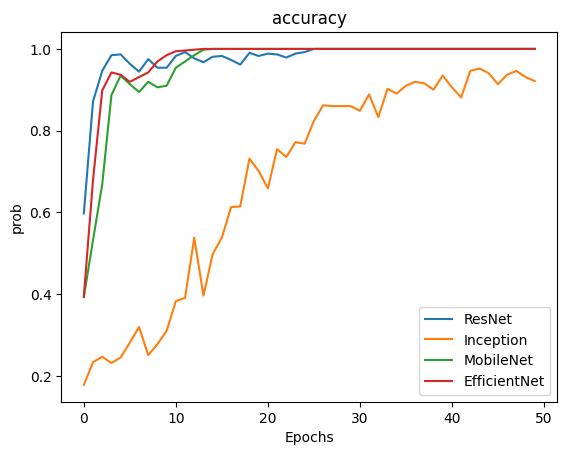
經過多輪測試,我們選擇 ResNet 模型作為最終模型,達成約 90% 的準確率。 其他模型如 Inception、MobileNet 與 EfficientNet 分別達到約 0.7、0.42 及 0.66 的準確率。 ResNet 模型在穩定性與準確率表現均優於其他模型。
.png)
這是ResNet測試後的混淆矩陣,可以看到在第0、2個分類,有圖片分別3張和2張預測錯誤,而其餘的都預測正確;在這五種分類中,每十張只會出現一次錯誤的機率。
.png)
這是程式設計時有加入的功能且輸出為txt檔之結果流程圖,有照相機功能、使用的模型數量、圖片載入順序、模型預測結果。
.png)
選用 ResNet -18 為這次的影像分類模型,並且要符合遊戲的內容,只設定輸出是否為天地之間的結果。
.png)
連結unity
因為劇情和因素關係,最後改成玩家透過遊戲中的檔案選取功能,上傳現實拍攝的場景圖片; 系統經辨識後,若結果符合任務條件,即可推動劇情發展,完成階段挑戰。
